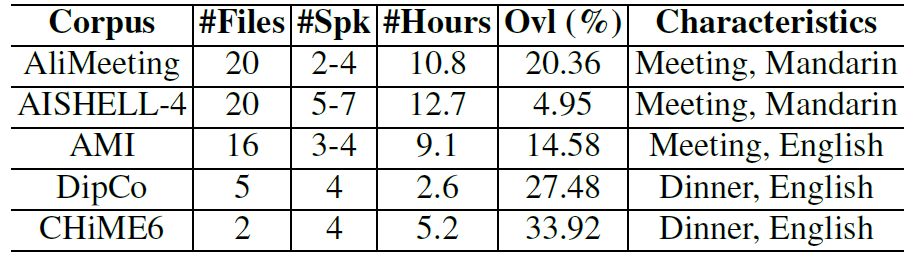
Covers both Mandarin and English conversations from diverse real-world sources.
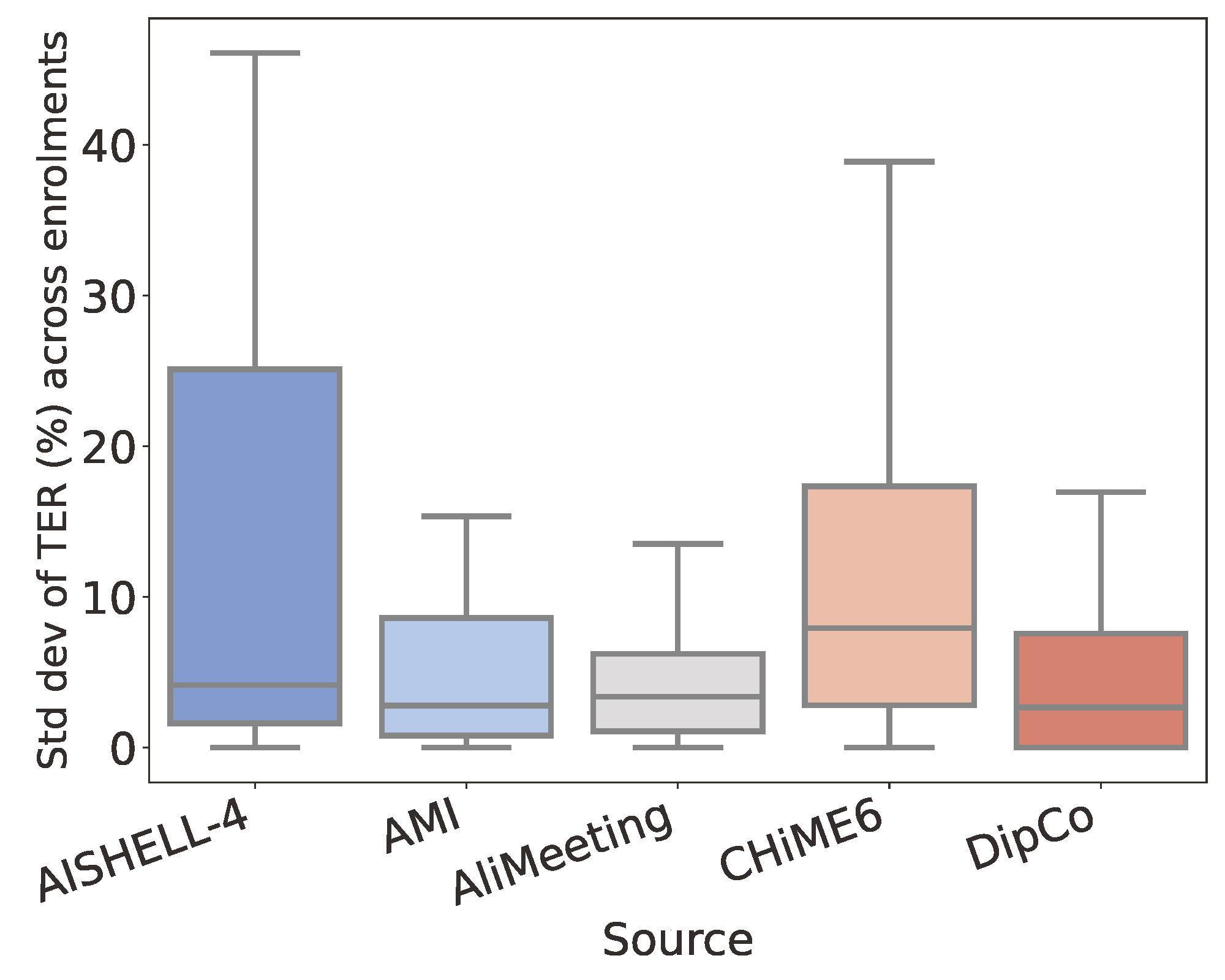
Covers diverse settings such as meeting rooms and dinner parties, drawn from datasets like AISHELL-4, AliMeeting, AMI, CHiME6, and DipCo.
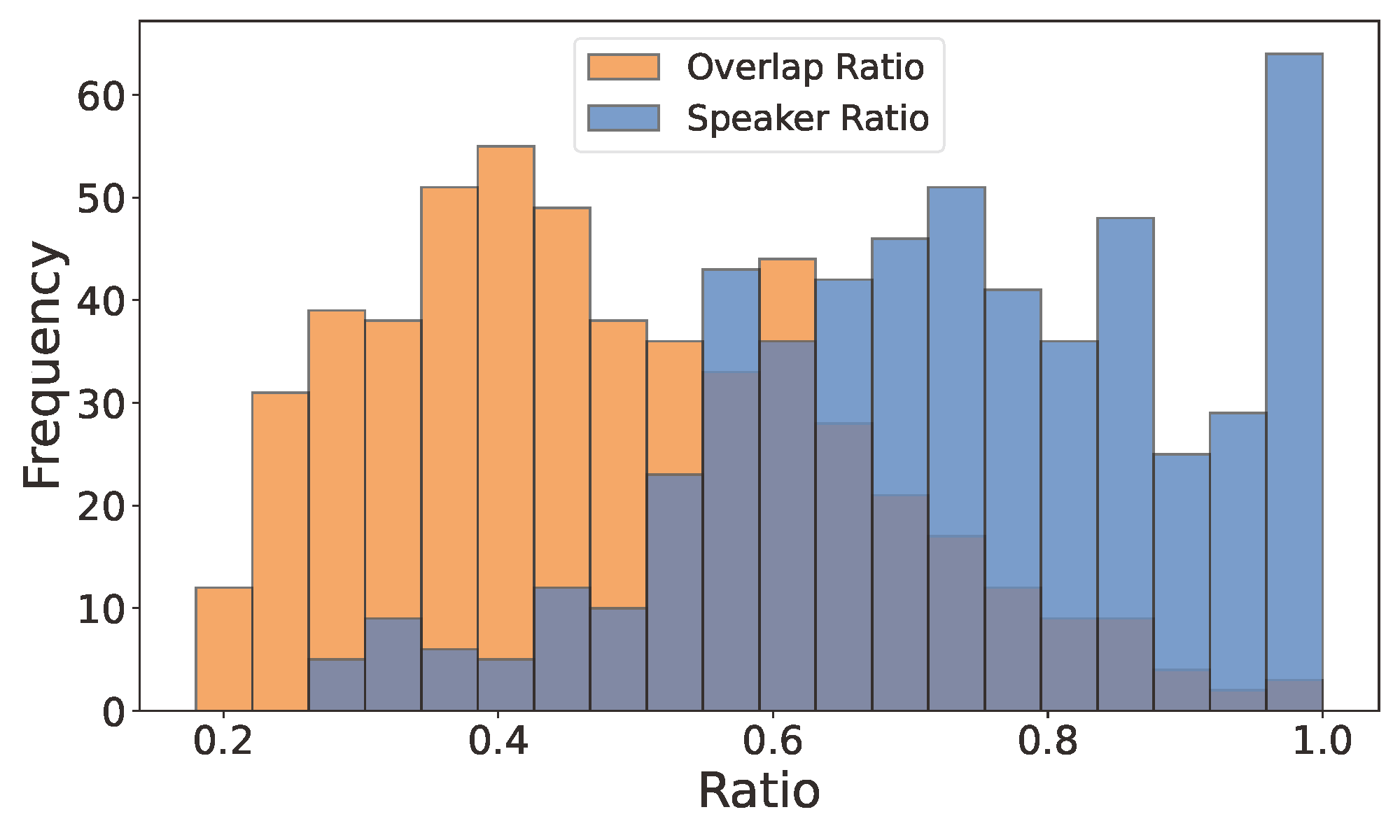
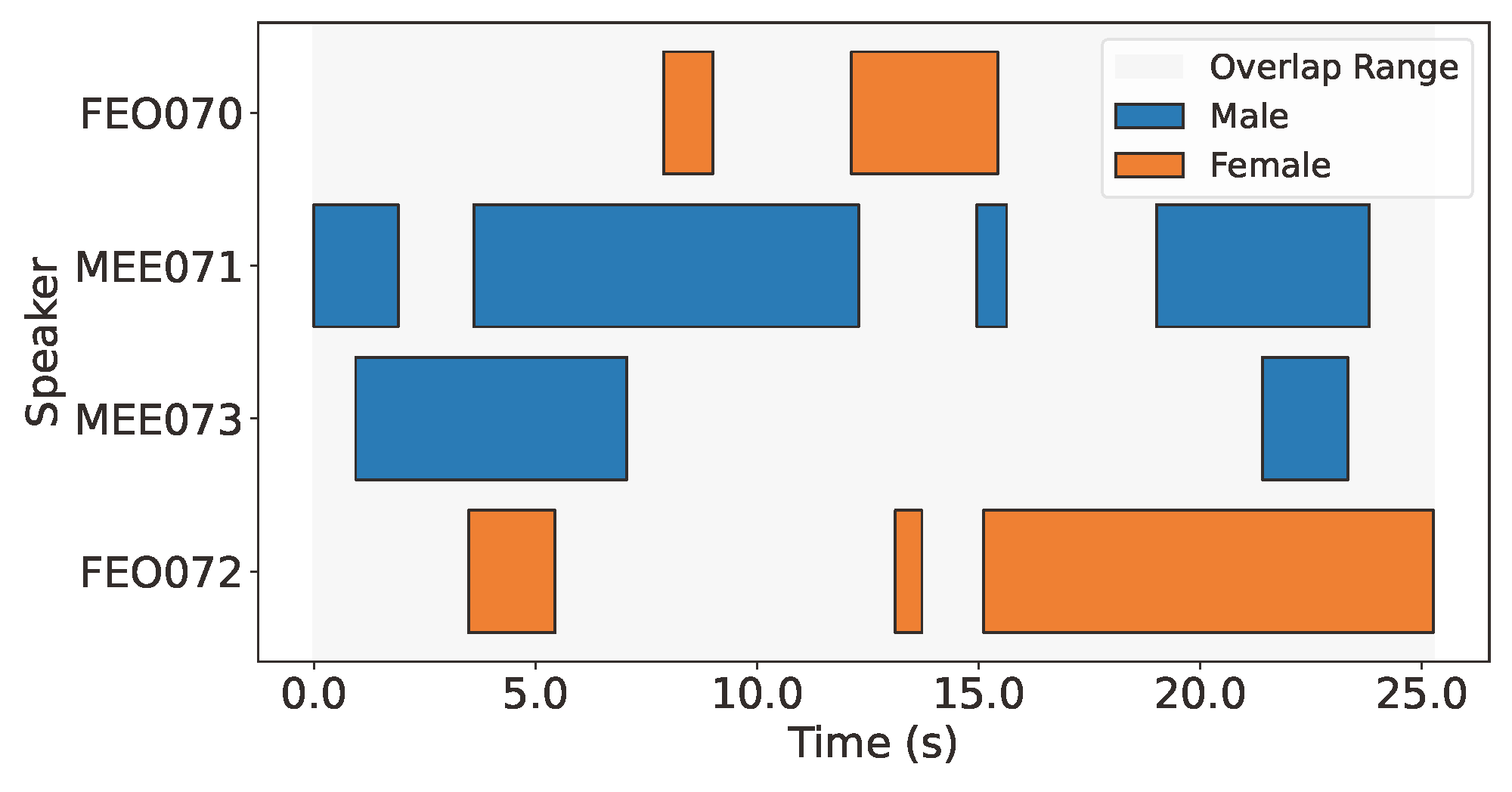
Each target speaker in REAL-T is provided with multiple enrollment utterance from different parts of the conversation
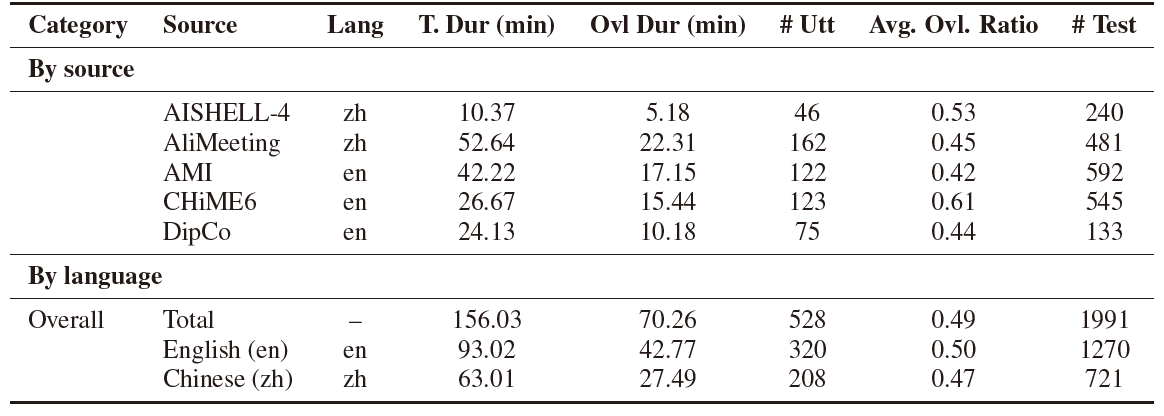
Moderate difficulty
150+ minutes total audio
70+ minutes overlapping speech
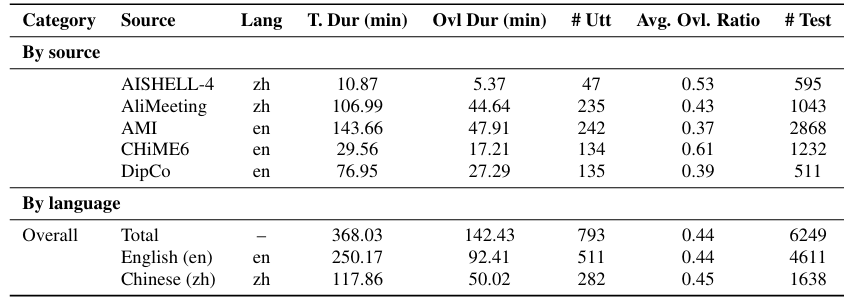
More challenging
360+ minutes total audio
140+ minutes overlapping speech
TSE models trained on synthetic data exhibit degraded performance when evaluated on realistic conversational scenarios.
Features
Some features about the REAL-T!
![]() Dataset available on
Hugging Face
Dataset available on
Hugging Face
 The REAL-T evaluation tool is open-sourced on
GitHub
The REAL-T evaluation tool is open-sourced on
GitHub
① Clone the repository and enter the project directory
git clone https://github.com/REAL-TSE/REAL-T.git
cd REAL-T② Create a Conda environment and install dependencies
conda create -n REAL-T python=3.9
conda activate REAL-T
pip install -r requirements.txt
# install wesep
git submodule init
git submodule update③ Set up environment variables
Please replace $PWD below with the absolute path to this project.
export PATH=$PWD/FireRedASR/fireredasr/:$PWD/FireRedASR/fireredasr/utils/:$PATH
export PYTHONPATH=$PWD/FireRedASR/:$PYTHONPATH
export PYTHONPATH=$PWD/wesep:$PYTHONPATH④ Automatically prepare dataset and checkpoints
bash -i ./pre.shRun inference script (You can adapt its input/output structure to suit your own TSE model)
bash -i ./run_tse.shRun both transcription and evaluation
bash -i ./transcribe_and_evaluation.sh 1 2The table below compares the performance of several recently proposed TSE models on the simulated Libri2Mix and PRIMARY test sets.
| Model | Training Data | Libri2Mix SI-SDR (dB) |
PRIMARY zh (%) |
PRIMARY en (%) |
|---|---|---|---|---|
| TSELM-L | Libri2Mix-360 | / | 331.73 | 192.39 |
| USEF-TFGridnet | Libri2Mix-100 | 18.05 | 67.98 | 87.27 |
| BSRNN | Libri2Mix-100 | 12.95 | 81.74 | 91.20 |
| Libri2Mix-360 | 16.57 | 69.80 | 73.61 | |
| VoxCeleb1 | 16.50 | 57.61 | 69.63 | |
| BSRNN_HR | Libri2Mix-100 | 15.91 | 70.03 | 78.96 |
| Libri2Mix-360 | 17.99 | 63.38 | 74.64 | |
| VoxCeleb1 | 16.38 | 58.77 | 66.46 |
Acknowledgement



